Method
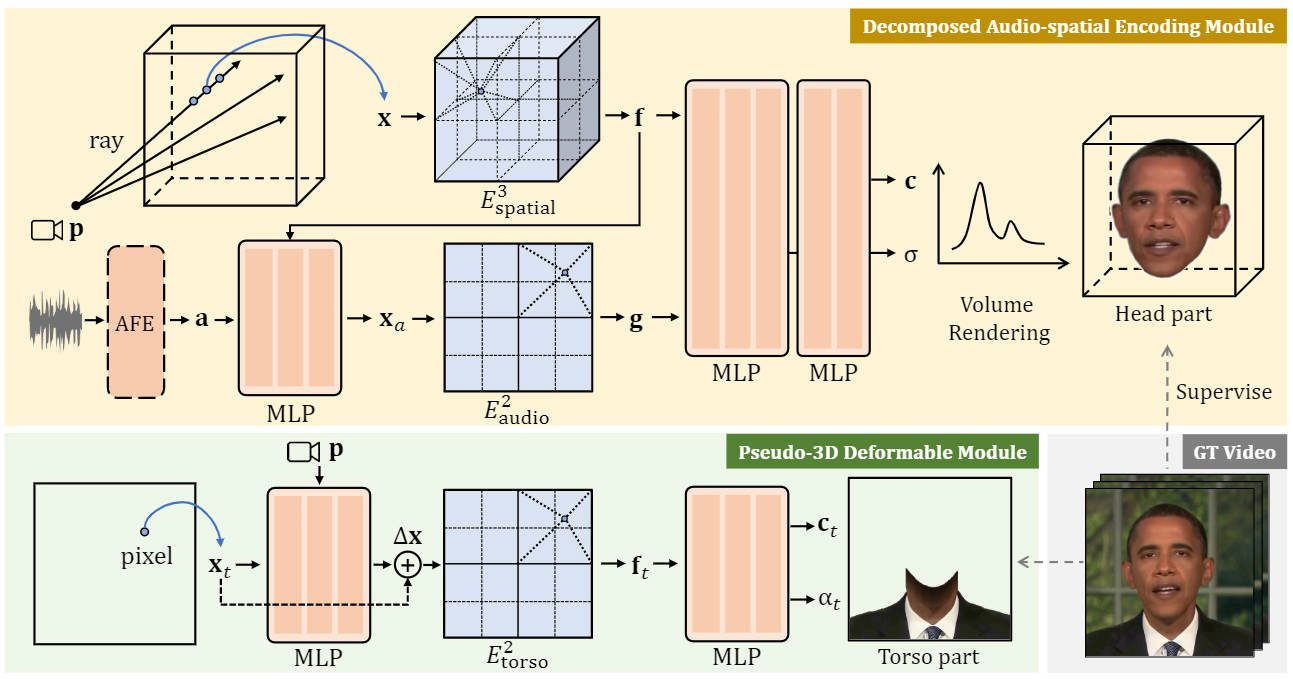
Our key insight is to explicitly decompose the inherently high-dimensional audio-guided portrait representation into three low-dimensional trainable feature grids:
1 Peking University
2 Baidu Inc.
3 S-Lab, Nanyang Technological University
While dynamic Neural Radiance Fields (NeRF) have shown success in high-fidelity 3D modeling of talking portraits, the slow training and inference speed severely obstruct their potential usage. In this paper, we propose an efficient NeRF-based framework that enables real-time synthesizing of talking portraits and faster convergence by leveraging the recent success of grid-based NeRF. Our key insight is to decompose the inherently high-dimensional talking portrait representation into three low-dimensional feature grids. Specifically, a Decomposed Audio-spatial Encoding Module models the dynamic head with a 3D spatial grid and a 2D audio grid. The torso is handled with another 2D grid in a lightweight Pseudo-3D Deformable Module. Both modules focus on efficiency under the premise of good rendering quality. Extensive experiments demonstrate that our method can generate realistic and audio-lips synchronized talking portrait videos, while also being highly efficient compared to previous methods.
Our key insight is to explicitly decompose the inherently high-dimensional audio-guided portrait representation into three low-dimensional trainable feature grids:
| GT | AD-NeRF | Ours |
| NVP | LSP | AD-NeRF | Ours |
| MakeItTalk | Wav2Lip | Ours |
| MakeItTalk | Wav2Lip | Ours |
Our method supports various video manipulation such as eye blinks, head poses, and backgrounds.
@article{tang2022radnerf,
title={Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition},
author={Tang, Jiaxiang and Wang, Kaisiyuan and Zhou, Hang and Chen, Xiaokang and He, Dongliang and Hu, Tianshu and Liu, Jingtuo and Zeng, Gang and Wang, Jingdong},
journal={arXiv preprint arXiv:2211.12368},
year={2022}
}