LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
ECCV 2024 (Oral)
Jiaxiang Tang1, Zhaoxi Chen2, Xiaokang Chen1, Tengfei Wang3, Gang Zeng1, Ziwei Liu2
1 Peking University 2 S-Lab, Nanyang Technological University 3 Shanghai AI Lab
Abstract
3D content creation has achieved significant progress in terms of both quality and speed. Although current feed-forward models can produce 3D objects in seconds, their resolution is constrained by the intensive computation required during training. In this paper, we introduce Large Multi-view Gaussian Model (LGM), a novel framework designed to generate high-resolution 3D models from text prompts or single-view images. Our key insights are two-fold: (1) 3D Representation: We propose multi-view Gaussian features as an efficient yet powerful representation, which can then be fused together for differentiable rendering. (2) 3D Backbone: We present an asymmetric U-Net as a high-throughput backbone operating on multi-view images, which can be produced from text or single-view image input by leveraging multi-view diffusion models. Extensive experiments demonstrate the high fidelity and efficiency of our approach. Notably, we maintain the fast speed to generate 3D objects within 5 seconds while boosting the training resolution to 512, thereby achieving high-resolution 3D content generation.
Pipeline
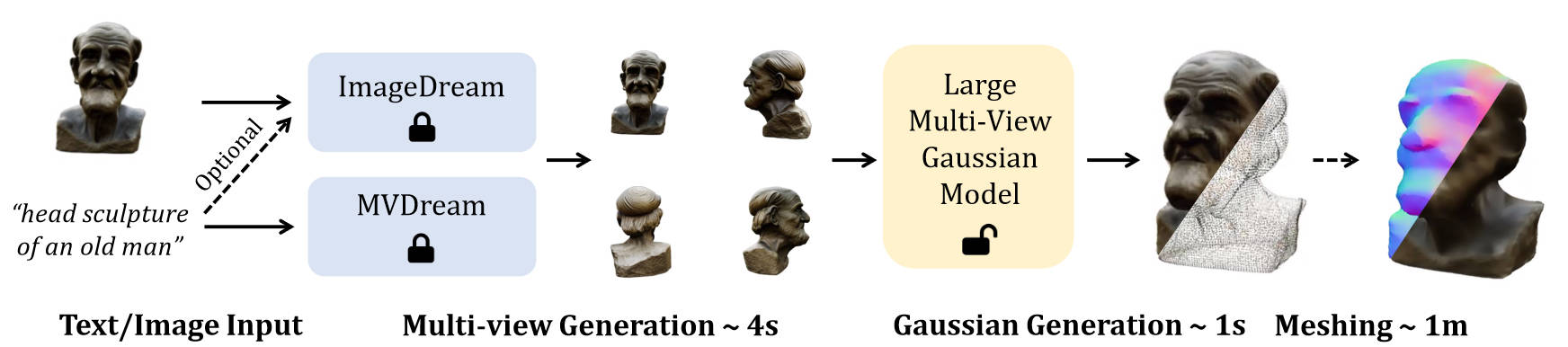
Architecture
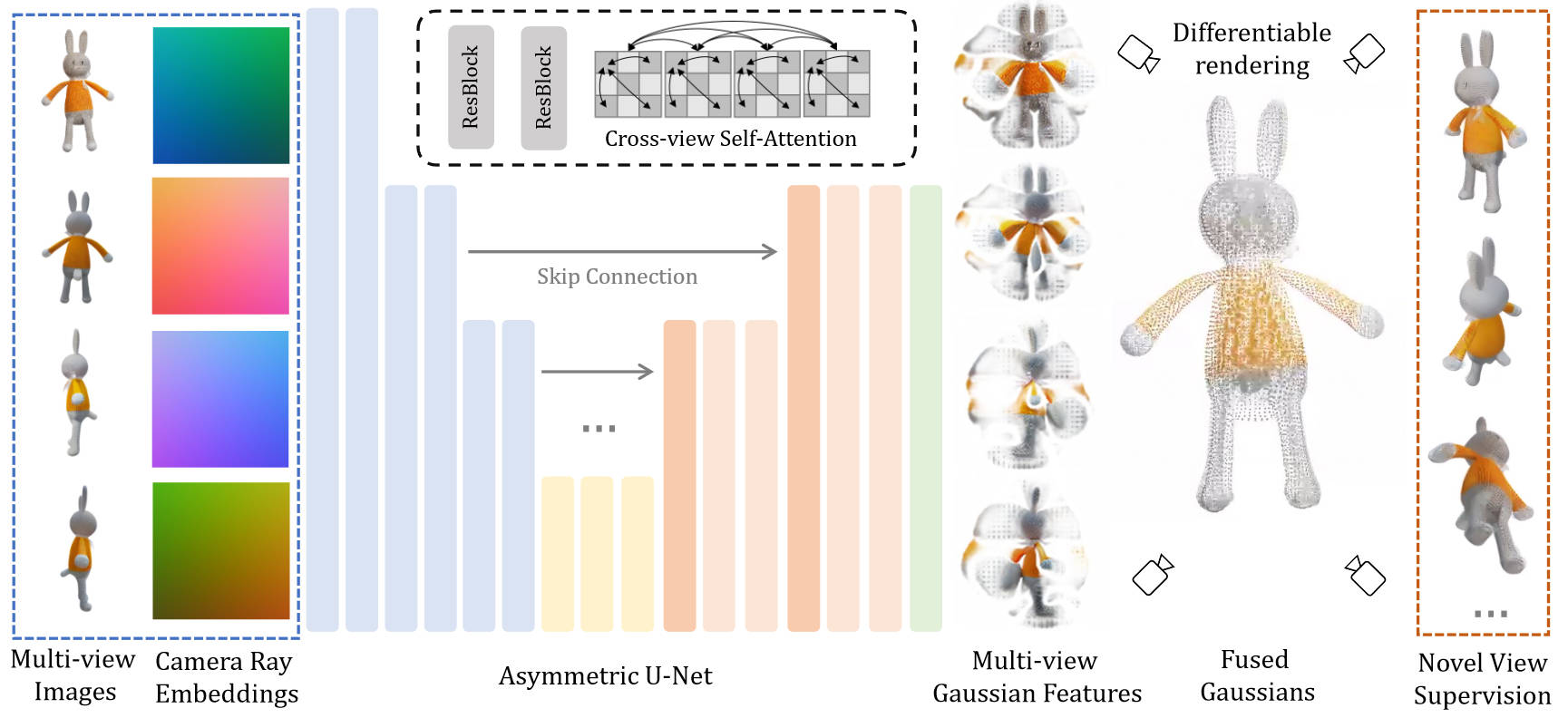
Image-to-3D
Text-to-3D
Diversity
Exported Meshes
Citation
@article{tang2024lgm,
title={LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation},
author={Tang, Jiaxiang and Chen, Zhaoxi and Chen, Xiaokang and Wang, Tengfei and Zeng, Gang and Liu, Ziwei},
journal={arXiv preprint arXiv:2402.05054},
year={2024}
}